MLOps (DevOps for machine learning) enables data science, and IT teams to collaborate and increase the pace of model development and deployment via monitoring, validation, and governance of machine learning models. Azure MLOps help to do that directly in IoT Edge. Any Enterprise can avail of several benefits by deploying MLOps like:
Increasing the value of your model, Integrating the developer and data science workflow, Deployment considerations, Simplified configuration, Increasing workflow efficiency. Register and track your ML models, Automate the end-to-end ML lifecycle with Azure Machine, Learning, and Azure Pipelines. Package and debug models, Validate and profile models, Continuous retraining.
By adopting DevOps for machine learning, the data scientist can use the following capabilities from the DevOps world: source control, reproducible training pipeline, model storage, and versioning, model packaging, model validation deployment, Monitoring models in production, and retraining of models. These capabilities are available individually, but Machin Learning DevOps integrates them seamlessly, allowing data scientists, developers, and ML engineers to collaborate efficiently.
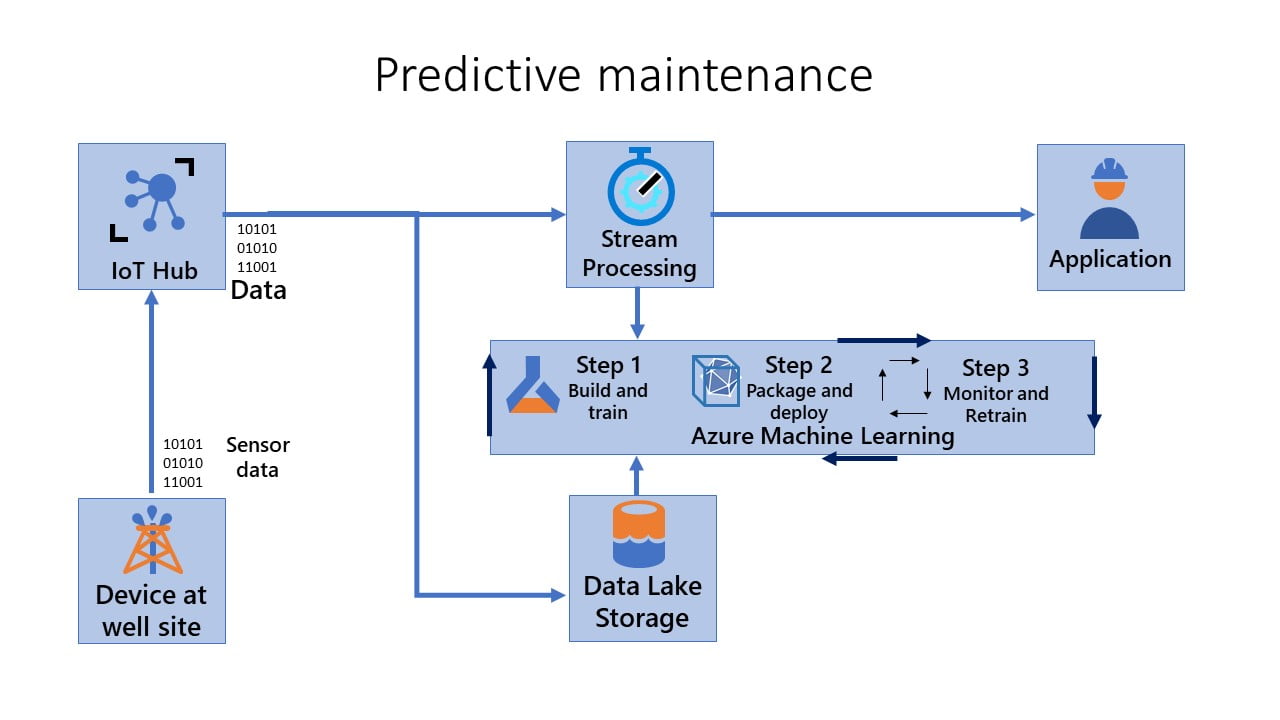
For this example, Let’s reconsider the Oil and Gas industry scenario we discussed previously. To recall, you’re responsible for maintaining thousands of oil and gas pumps operating in remote/offshore locations. Your team must rapidly identify and fix faults in the field. You want to build and deploy a predictive maintenance system for the pumps using the data captured from the sensors to create up-to-date machine learning models. The models should reflect the current state of the data; that is, the model shouldn’t be stale concerning the data drift. Finally, because you’re using an IoT Edge scenario, the models should be able to run on edge devices (if necessary in an offline mode).
DevOps for Machine Learning Steps with Azure IoT Edge
To address this scenario, using MLOps for Edge devices, you can consider three pipelines.
- Build and Train (Step 1)
- Package and Deploy (Step 2)
- Monitor and Retrain (Step 3)
Step 1 – Build and Train:
In this step, you create reproducible models and reusable training pipelines. When the CI pipeline gets triggered, every time code is checked in. It publishes an updated Azure Machine Learning pipeline after building the code and running a suite of tests. The build pipeline includes a number of unit tests and code quality tests.
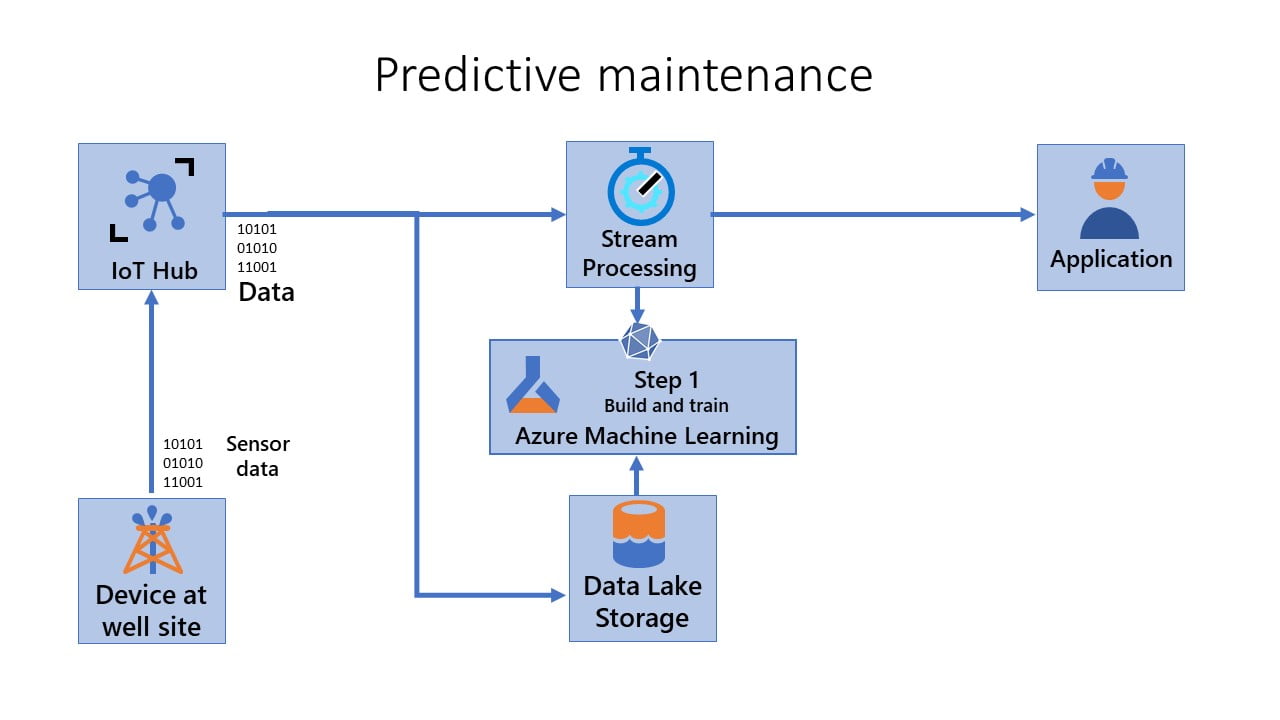
Step 2 – Package and Deploy:
In this step, you package, validate, and deploy models. In this pipeline, you’ll operationalize the scoring image and promote it safely across different environments. The pipeline gets triggered every time a new artifact is available. The registered model is packaged together with a scoring script and Python dependencies (Conda YAML file) into an operationalization Docker image. The image automatically gets versioned through Azure Container Registry. The scoring model is deployed on container instances where it can be tested. If it’s successful, the scoring image is implemented as a web service in the production environment.
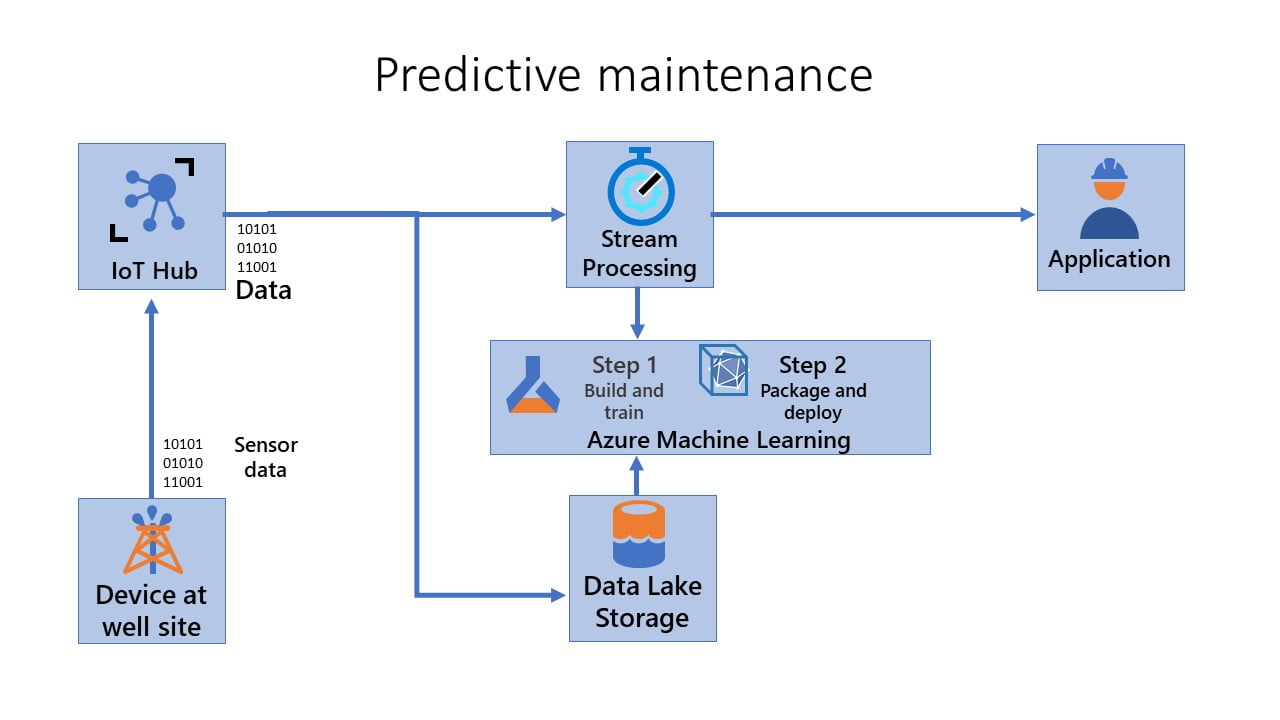
Step 3 – Monitor and Retrain:
Explain & observe model behavior and automate the retraining process. The machine learning pipeline orchestrates the process of retraining the model asynchronously. Any retraining can be triggered on a schedule or when new data becomes available by calling the published pipeline REST endpoint from the previous step. In this stage, you retrain, evaluate, and register the model.
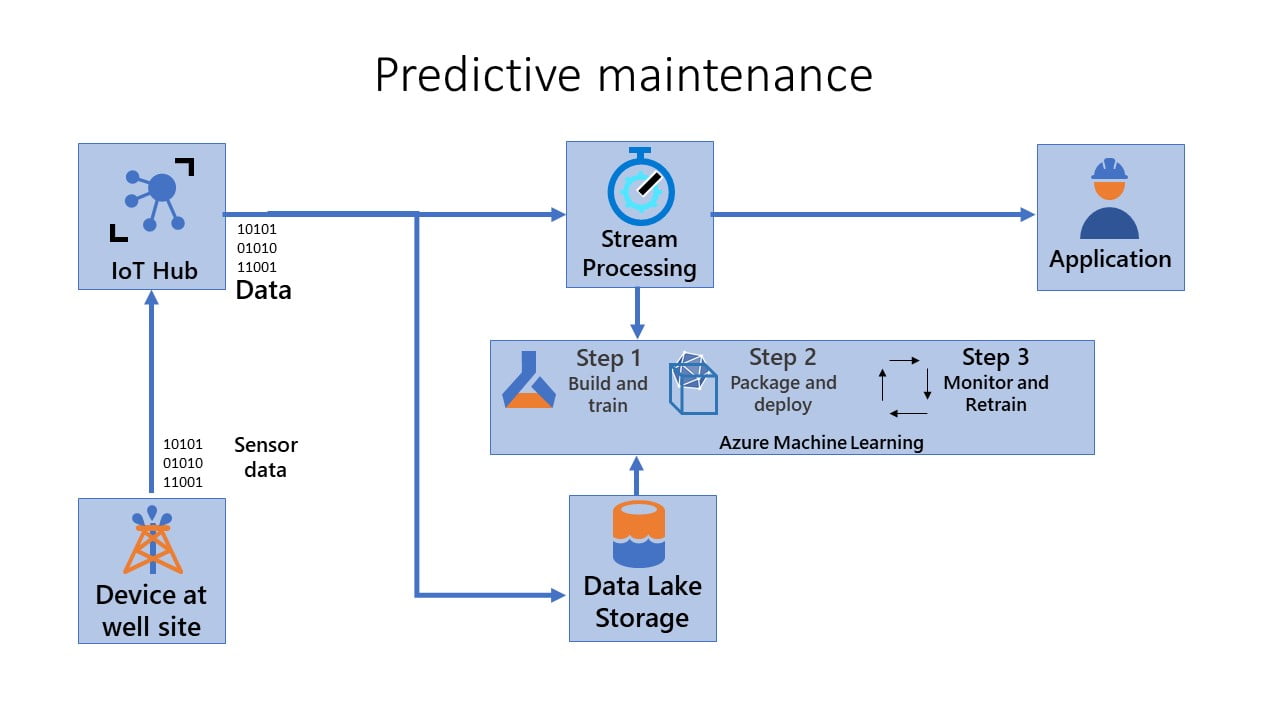
The final flow is as shown below